One of the things that is very frustrating when trying to do any sort of analysis of data in CDS is the fetch aggregate limit. If you haven’t come across this before, this is a hard limit of 50,000 records that it will process when trying to calculate aggregate values such as sum, count etc. If you try to run a query in FetchXML Builder for example that needs to process more than 50k records you’ll get an “AggregateQueryRecordLimit exceeded” error.
The documentation advises working around this error by breaking up your query into smaller chunks and then aggregating the results. This will work, but involves a lot more thought, time and scope for error. Improving this experience was one of my main objectives for SQL 4 CDS.
T-SQL Results
My first simple test was to do a bulk import into the Lead entity and then run a simple queyr:
SELECT count(*) FROM lead
The result was simple but very pleasing:
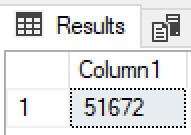
Woohoo! It looks like the aggregate limit has gone for T-SQL!
Just to check this isn’t a special case for this one query (which you can do via the SDK with the RetrieveTotalRecordCountRequest), I also tried:
SELECT firstname, COUNT(*) FROM lead GROUP BY firstname ORDER BY 2 DESC
and a number of my other common data quality checks that use aggregation and they all worked correctly. 👍
New Options
FetchXML provides the most common aggregate options:
- COUNT
- MIN
- MAX
- SUM
- AVG
These can be used across the entire result set, or you can use GROUP BY to get the results for each group. Another bugbear of mine has been the lack of an equivalent to the HAVING clause.
So I was pleased to find we now also have support for:
- all the rest of the aggregate functions supported by T-SQL to do more advanced analysis such as standard deviation and variance
- a
HAVINGclause to filter the aggregated results GROUP BY xxx WITH ROLLUPto generate sub-totals and grand totals- window functions to generate running totals and row numbers in non-aggregated results
Thoughts
So this gets me to thinking, why is it different in T-SQL than FetchXML? Both are, after all, querying the same underlying database.
The aggregate query limit has been around for a long time – is this just a hold-over from when the hardware couldn’t cope with this as well as it can today, and could be removed entirely now?
Or is it that the T-SQL endpoint is running in such a fundamentally different way than the rest of the platform that the limit is either not necessary or too difficult to implement?
My gut feeling is that it’s more towards the later. After seeing some of the other queries that are now possible that aren’t in FetchXML, and some of the ways that it’s not returning the results I’d expect just yet, my current thought is that the T-SQL endpoint does some re-writing of the incoming SQL query to make it safe, then passes it on to the underlying Azure SQL Database. With the variety of ways that you can write a SQL query it must be very hard to ensure that you get the same results after the rewriting that you’d expect without it, so this might be a case of caution on the part of the product team to avoid breaking too many queries.
But at the same time I have to ask, if we can get this now via T-SQL, can we have the limit removed for FetchXML too please? 🙏
Other Posts
This is part of a series of posts on the T-SQL endpoint, read more about it:
Hello Mark,
I installed SQL 4 CDS this week in a try to get data from Microsoft D365.
I have a background in Oracle SQL. I would like to know which sql variant this is?
I tried to get a sum(nvl(hours,0)) and it returned an error.
SQL 4 CDS uses the T-SQL dialect. I’m not familiar with Oracle, what does the
nvlfunction do?it returns the value if the field is null, so: sum nvl(amount,0)) the null causes the sum to error, the nvl function gives a numeric value and thus no error