Did you notice a new option appear when you create a new table in Dataverse recently?
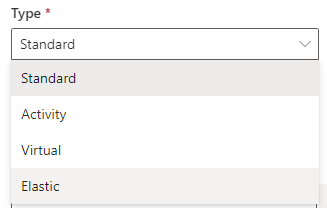
What does it mean, and what happens if you select it?
Data Storage
Behind the scenes, Dataverse stores standard tables in an Azure SQL database. Elastic tables, on the other hand, use Cosmos DB. This difference gives elastic tables some big benefits, but does come at a cost of extra limitations as well. I’ve tried to outline these below to help illustrate when it might be useful to choose elastic tables and when to stick with standard tables.
Performance
The main benefits of elastic tables are in terms of scale and performance. Cosmos DB, and therefore Dataverse elastic tables, can easily scale to huge volumes of data and maintain very fast read & write times.
A key feature to maintaining this performance benefit is the PartitionId column that is automatically created in each elastic table. Partitioning the data by using different values in this column allows Cosmos DB to more intelligently store related data together for faster access. Any queries against an elastic table should also filter the data by this column – this lets Cosmos DB know that you’re only interested in data within one of these partitions and so limit the amount of data it’s got to consider to get the answer.
For example, if you use an elastic table to hold a list of people which you will regularly need to search by last name, you might want to store the last name in the PartitionId column. This will make queries such as
<fetch top="50">
<entity name="new_elastictable">
<attribute name="new_firstname" />
<attribute name="new_lastname" />
<filter>
<condition attribute="partitionid" operator="eq" value="Carrington" />
</filter>
</entity>
</fetch>
much faster when you have a large number of records than
<fetch top="50">
<entity name="new_elastictable">
<attribute name="new_firstname" />
<attribute name="new_lastname" />
<filter>
<condition attribute="new_lastname" operator="eq" value="Carrington" />
</filter>
</entity>
</fetch>
Partitioning and Retrieve
The partition key you use in the partitionid attribute becomes a key part of the identity of the record. To read a record, in addition to the primary key field you’ll also need the partition value.
If you try to create a record in a partition then immediately read it like:
var id = svc.Create(new Entity("new_elastictable")
{
["partitionid"] = "123",
["new_name"] = "Hello elastic tables!"
});
var record = svc.Retrieve("new_elastictable", id, new ColumnSet("new_name"));
you’ll get an error indicating the record doesn’t exist. The ID is correct, but the Retrieve call is missing the partitionid. To make this work we can either add a new partitionId parameter to the RetrieveRequest:
var request = new RetrieveRequest
{
Target = new EntityReference("new_elastictable", id),
ColumnSet = new ColumnSet("new_name"),
["partitionId"] = "123"
};
var response = (RetrieveResponse) svc.Execute(request);
or we can use the alternate key that is automatically created for us that combines the primary key field and the partitionid:
var request = new RetrieveRequest
{
Target = new EntityReference("new_entityreference", new KeyAttributeCollection
{
["new_entityreferenceid"] = id,
["partitionid"] = "123"
});
};
var response = (RetrieveResponse) svc.Execute(request);
You can also use this extra partitionId parameter for RetrieveMultiple as well, to target your query at a specific partition. This should improve the performance of your query with large datasets.
var request = new RetrieveMultipleRequest
{
Query = new QueryExpression("new_elastictable")
{
ColumnSet = new ColumnSet("new_name"),
Criteria = new FilterExpression
{
Conditions =
{
new ConditionExpression("createdby", ConditionOperator.EqualUserId)
}
}
},
["partitionId"] = "123"
};
var response = (RetrieveMultipleResponse)svc.Execute(retrieveMultiple);
Data Imports
You can use the same methods as normal to load data into elastic tables, but you’ll definitely want to look at the newer SDK messages CreateMultiple, UpdateMultiple, UpsertMultiple and DeleteMultiple for doing large data loads. These let Dataverse really take advantage of the performance benefits of Cosmos DB to speed up your processing.
In the chart below I’ve compared the time (in seconds) to create 100 records in an elastic table using 3 different methods:
// 1: Single-threaded, individual Create requests
for (var i = 0; i < 100; i++)
{
var entity = new Entity("new_elastictable")
{
["name"] = "Test",
["partitionid"] = "123",
["ttlinseconds"] = 120
};
svc.Create(entity);
}
// 2: 100 CreateRequests within an ExecuteMultipleRequest
var multiple = new ExecuteMultipleRequest
{
Settings = new ExecuteMultipleSettings
{
ContinueOnError = false,
ReturnResponses = true
},
Requests = new OrganizationRequestCollection()
};
for (var i = 0; i < 100; i++)
{
var entity = new Entity("new_elastictable")
{
["name"] = "Test",
["partitionid"] = "123",
["ttlinseconds"] = 120
};
multiple.Requests.Add(new CreateRequest { Target = entity });
}
svc.Execute(multiple);
// 3: 100 records in a single CreateMultiple request
var entities = new EntityCollection();
entities.EntityName = "new_elastictable";
for (var i = 0; i < 100; i++)
{
var entity = new Entity("new_elastictable")
{
["name"] = "Test",
["partitionid"] = "123",
["ttlinseconds"] = 120
};
entities.Entities.Add(entity);
}
svc.Execute(new CreateMultipleRequest
{
Targets = entities
});
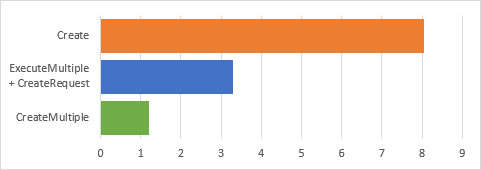
The results are pretty stark – CreateMultiple, although doing a very similar job to the ExecuteMultiple request, runs a full 3x faster!
Time-to-live (“auto-destruct”)
If you have data that is temporary, and you know at the point you create it how long you’ll need to keep it for, elastic tables has another great built-in feature. By setting the ttlinseconds column, you are indicating that the record should be automatically deleted that many seconds after it was created or last modified.
The deletion happens automatically in the background. It’s not precise – records won’t be removed before their TTL has expired, but it might be a few seconds afterwards – but this gives you more control over automatically deleting records than you might be able to achieve with bulk delete.
Reusing the Cosmos DB Session
Cosmos DB has another important concept of consistency levels. Elastic tables appear to use the Session consistency level – reads & writes performed within the same session are guaranteed to be performed in the expected order, but outside that session you may see differences for a period of time.
If you need to ensure that, for example, you can read the changes to a record immediately after creating it, you’ll need to ensure you’re reusing the same session for both requests. Dataverse exposes the details of this session through some new request and response parameters:
string sessionToken = null;
for (var i = 0; i < 100; i++)
{
// Create the record
var createReq = new CreateRequest
{
Target = new Entity("new_elastictable")
{
["partitionid"] = "123",
["new_name"] = $"Elastic record {i}"
};
};
// Include the existing session token if we have one
if (sessionToken != null)
createReq["SessionToken"] = sessionToken;
var createResp = (CreateResponse) svc.Execute(createReq);
// Save the session token for the next request
sessionToken = (string) createResp["x-ms-session-token"];
}
Querying JSON data
As well as the standard ways of querying data such as FetchXML and OData, Elastic tables also support the native Cosmos DB SQL-like query language via the new ExecuteCosmosSqlQuery request.
One great thing about this option is that you can store semi-structured data in a text column in your Elastic table. So long as the text format is set as JSON you can query the values inside that field in a structured way
Limitations
You’ll notice a lot of features are disabled when you choose to create an elastic table – things like duplicate detection, adding activities and connections.
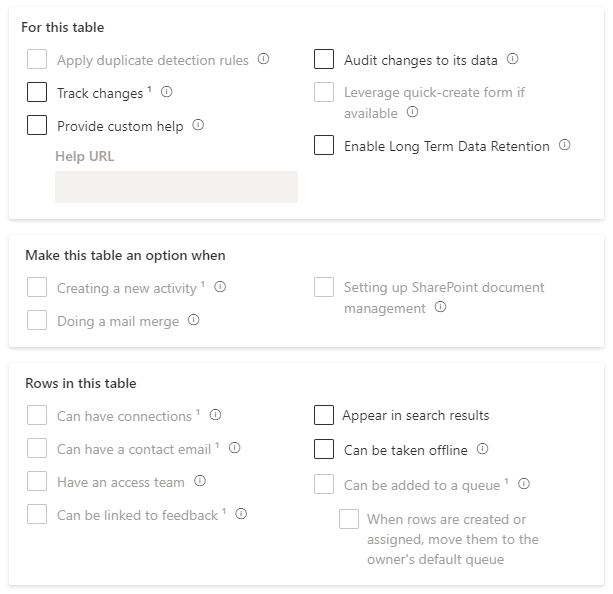
If you try to query the data with FetchXML you’ll also find that some features aren’t supported, such as joining to other tables with a <link-entity>
Although you can’t use joins in your queries, you can create lookup columns. However, because the elastic tables aren’t stored in the SQL database you can’t use options like cascade delete (where the related records in the elastic table are deleted automatically when the parent record is deleted).
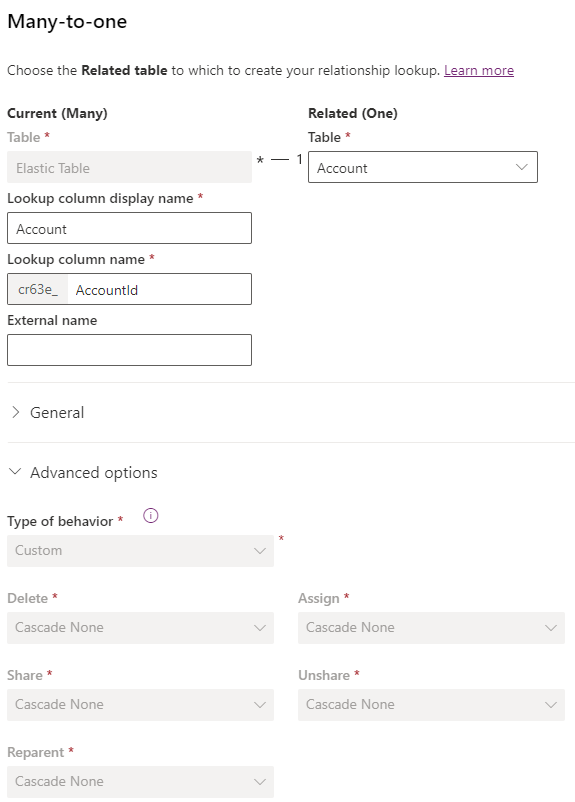
In the maker portal you’ll need to create the relationship rather than creating the lookup column directly, otherwise you’ll get an error like:
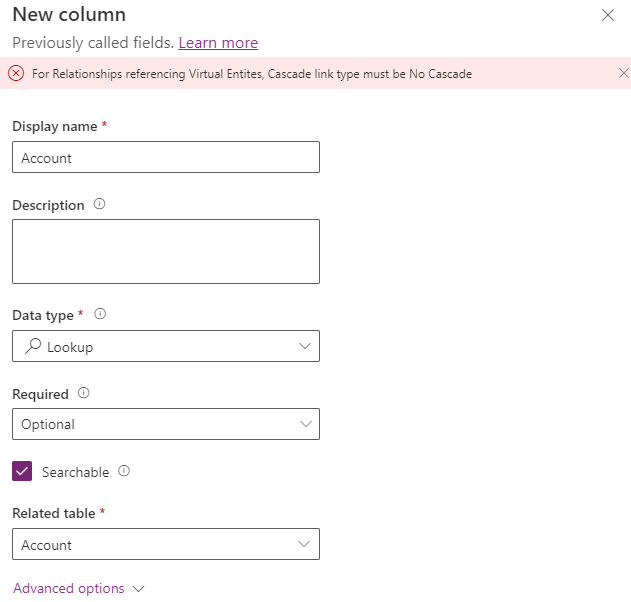
Use Cases
Because of limits like not being able to use joins to query the data, and the benefits of scale, performance and time-to-live settings, I think elastic tables really lend themselves best to tables that store large amounts of stand-alone data that has a consistent query pattern that fits with partitioning, or child records for other tables where the parent record ID could be used as the partition key.
Things like logs of external events might fit well with this – you could set the partition key to the thing the log entry is regarding so you can quickly query for related logs, and use the TTL options to automatically remove old logs.
More Developer Resources
As well as the links earlier in the post, there’s more information available for developers on Microsoft Learn as well:
and some sample code for:
Great post Marc!
Very interesting. Thanks
Very nice article. Thanks for the great insight about elastic table. Earlier MS stored the audit data in this type of table, changed now. Thanks again
Audit logs seem to be stored in a specialised version of this, still using Cosmos DB at the back end but with much of the complexity hidden.
Hi Mark,
thank you for great summary. But what about the security or governance model? Is there the same logic as for standard tables?
Yes, you can still apply security roles in the same way as standard tables, and they can be set as user- or organization-owned.
Check out some of the sample code published for these tables:
SDK:
– https://github.com/microsoft/PowerApps-Samples/tree/master/dataverse/orgsvc/C%23-NETCore/ElasticTableOperations
– https://github.com/microsoft/PowerApps-Samples/tree/master/dataverse/orgsvc/C%23-NETCore/xMultipleSamples
Web API: https://github.com/microsoft/PowerApps-Samples/tree/master/dataverse/webapi/C%23-NETx/ElasticTableOperations
SDK Link to github broken. Moved here:
https://github.com/microsoft/PowerApps-Samples/tree/master/dataverse/orgsvc/CSharp-NETCore/ElasticTableOperations