In the world of data technologies, you’ll probably see data lakes appearing more and more often. I’d like to take a closer look at the Azure Data Lake and how it works with the wider Azure data ecosystem.
What is a data lake?
A data lake is essentially a data storage technology. You can add data from various sources and store it in multiple different formats. It is not a database – it doesn’t provide any native capability for querying the data you store in it. However, the data in it can be quickly and efficiently loaded into other different database technologies for querying in different ways.
How do I get one?
Azure has always had a way of storing data. The Azure Storage account is one of the fundamental building blocks, and it’s been around from the start. The current data lake option in Azure, Azure Data Lake Storage Gen 2, is an evolution of this.
In the Azure Portal, create a new resource and select the standard Storage Account resource. On the Advanced page, enable the “Hierarchical Storage” option. That’s it – your storage account is now a data lake!
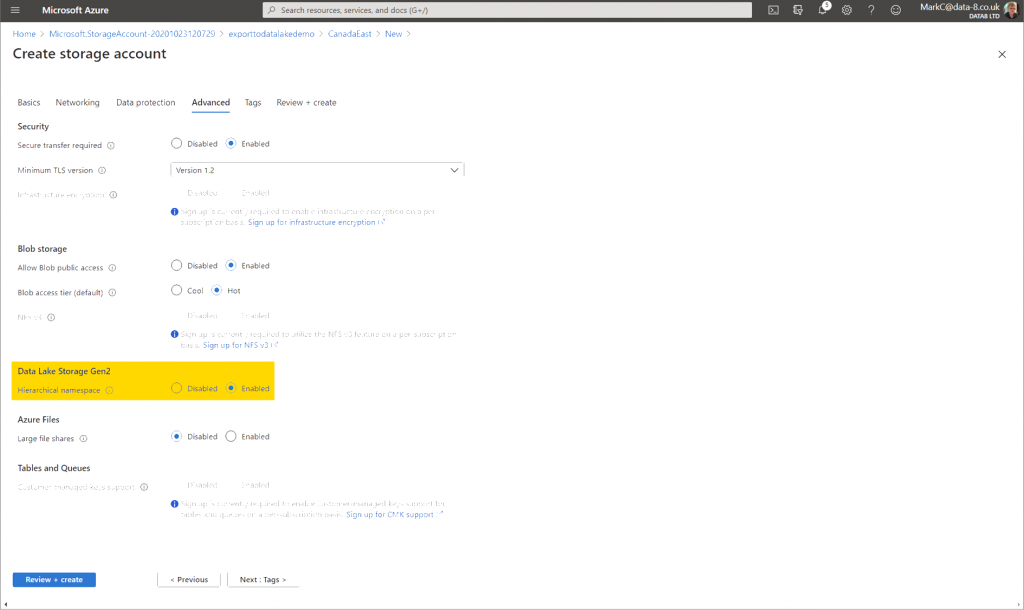
So what’s the difference?
The real difference this makes compared to a regular storage account is the way you can store blobs (files) in hierarchies. Without this option, you can give a blob a name like data/accounts/myaccounts.csv and it would appear to be stored in a directory, but really the container just stores a flat list of files that contain the full name including the directory prefixes. This makes it inefficient to perform operations on these pseudo-directories – renaming a “directory” could mean renaming thousands of individual files.
With the hierarchical namespace option enabled, directories become real subsets of files rather than just a naming convention. This lets you perform common operations such as moving or renaming directories in a single operation rather than repeating them for each file within them.
This might sound like a trivial change, but it can make a huge difference to the performance of data analytics workloads.
Why is it important?
With more data technologies becoming available, it’s important to be able to move data efficiently from one to the other. In Azure we can see the data lake becoming the common data storage platform that other technologies can all use. If you store your data in Azure Data Lake it becomes accessible to platforms including:
- Power BI, to visualise your data and perform self-service analysis
- Synapse Analytics, to create a scalable data warehouse to drive analytics and reporting
- Data Factory, to integrate your data with other sources
- Databricks, to investigate your data with powerful machine learning, AI and data science tools
I’ll be looking at each of these in some more detail over the next few weeks.