You can ensure your query only produces each row once using the distinct attribute. For example, if you have multiple entries for the same company name you can get the list of unique names using:
<fetch distinct="true">
<entity name="account">
<attribute name="name" />
</entity>
</fetch>
This option gets applied automatically whenever you create a query using Advanced Find. This is particularly useful when you add a join onto a related child entity. For example, this query:
<fetch>
<entity name="account">
<attribute name="name" />
<link-entity name="contact" from="parentcustomerid" to="accountid" link-type="inner">
<filter>
<condition attribute="firstname" operator="eq" value="Mark" />
</filter>
</link-entity>
</entity>
</fetch>
The intent here is to get a list of accounts that have a contact called Mark. However, if an account has two Marks, that account will be in the resulting list twice. Adding the distinct attribute makes sure the user gets what they were probably expecting, which is a list of unique accounts.
Unique Identifiers
One other interesting side effect of using distinct is that you no longer get the primary key of the entity back automatically. If you run the query:
<fetch>
<entity name="account">
<attribute name="name" />
</entity>
</fetch>
As well as getting the account name back, you’ll also automatically get the accountid as well.
When you apply distinct, this goes away. This makes sense if you think about it. Imagine you have two accounts with the same name. If the accountid was automatically included, that would make the records unique. You would still get two rows back from your query, regardless of whether or not you used distinct.
If the purpose of using distinct is to eliminate duplicate rows introduced by a join onto a child entity as shown above though, you probably do want to get a row back for each of your top-level entity type. In that case you will need to explicitly include the primary key attribute in your query, e.g.
<fetch distinct="true">
<entity name="account">
<attribute name="accountid" />
<attribute name="name" />
<link-entity name="contact" from="parentcustomerid" to="accountid" link-type="inner">
<filter>
<condition attribute="firstname" operator="eq" value="Mark" />
</filter>
</link-entity>
</entity>
</fetch>
Truncation
One “gotcha” to be aware of. Any text values will be truncated to 2,000 characters before the distinct operation is applied. If you have longer values, e.g. descriptions or the contents of attachments in the annotation entity, any extra data after the first 2,000 characters will be lost.
Quite why this would be is a bit of a mystery. My best guess is that these fields used to be stored in a SQL Server ntext field which couldn’t be used in a SELECT DISTINCT query, so to work around this problem Dynamics CRM would cast these values to an nvarchar(2000) value which could be used instead. You can see this in the generated SQL:
<fetch distinct="true" top="10">
<entity name="annotation">
<attribute name="documentbody" />
</entity>
</fetch>
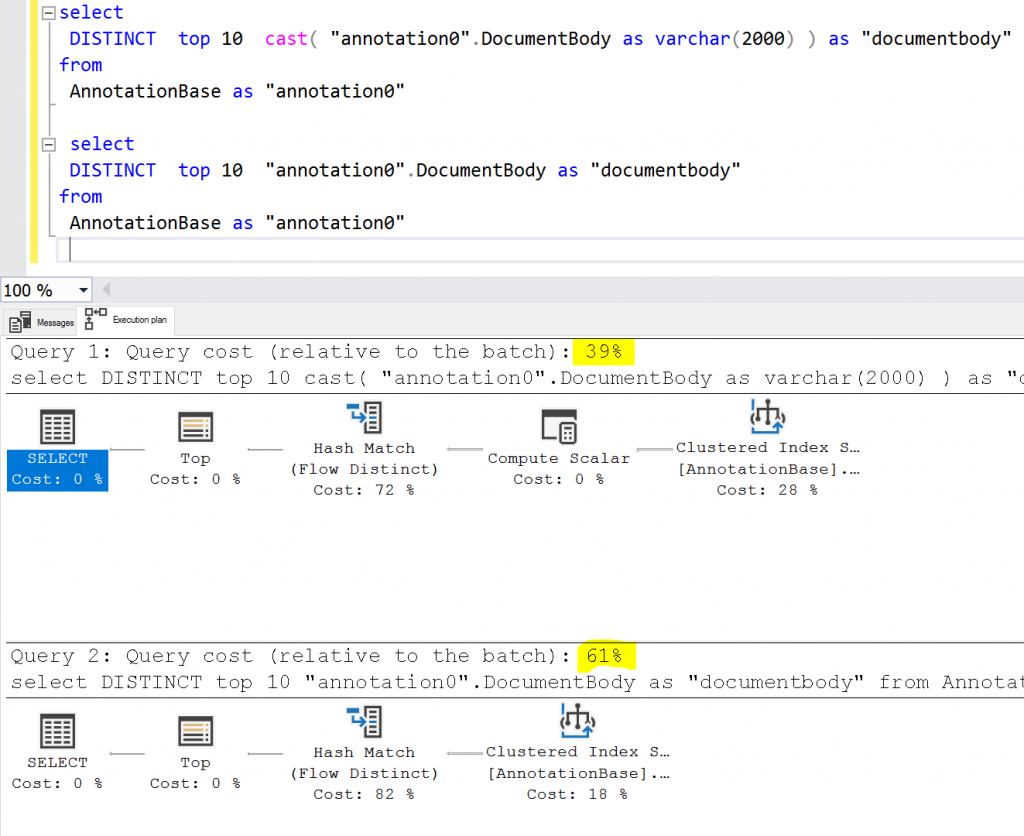
select DISTINCT top 10 cast( "annotation0".DocumentBody as varchar(2000) ) as "documentbody" from AnnotationBase as "annotation0"
As these columns are now stored using an nvarchar(max) field which can be used directly in a SELECT DISTINCT query I guess this behaviour is still in place for backwards compatibility reasons, although it does give about a 35% performance improvement:
SQL Equivalent
Apart from this once caveat of long text fields, this is directly equivalent to the SQL DISTINCT keyword.
Great post
This is a great series that pulls together everything that you’d want to know about FetchXML. I only occasionally need to use FetchXML, and I have this bookmarked at the ready when I do.
I tried to use distinct in the following query but get a “Key property ‘cra44_timeentriesid’ of type ‘Microsoft.Dynamics.CRM.cra44_timeentries’ is null. Key properties cannot have null values.” error.
A bit of searching shows this is just what happens when you use distinct inside the Flow Dataverse connector which is a real shame. Doesn’t look like there are any quick fixes.
I can’t see your query in the comment unfortunately. Do you have the cra44_timeentriesid attribute as part of your query? My guess is the Power Automate connector is assuming the primary key attribute will always be present and fails if it’s missing or using a different alias. Not very helpful if you’re trying to use distinct or aggregate queries I agree. My best suggestion would be to open a support case with Microsoft to try to raise the visibility of the problem.
After some trial and error I found you can fix this by using the name of your entitiy’s primary key attribute as an alias for the attribute you actually want to perform distinct on. For example, the following gave me the desired results:
Can I use distinct on only one returned attribute. For example, I want to return all unique account names but also have the city column which should not be used in the distinct operation.
No, DISTINCT always applies to the entire query.
Hi, thanks for this great post! Is it suppose to works with link-type=”outer” ? Because with this fetch, I have duplicate values of cic_disponibilitesid.
I can’t see your query I’m afraid, but yes it should work with outer joins. The distinct operation is applied across all the columns being returned by the query, so if you have one main table joined to a child table you’ll get the same main record returned multiple times. If you need to post your query for more clarification, please encode it first with https://emn178.github.io/online-tools/html_encode.html or similar
Hi Mark
Interestingly I made such query with distinct value on a scenario with a “basket”, a custom intersection table and account. Where i started the query from the intersection table and linked inner the account from accountid. Order by account attribute name. I have removed all other attributes from this view (and xrm toolbox was unhappy ‘you should really include the primary id ‘intersectiontableid”.
The interesting point is, that in xrm toolbox i get the result i want: the records distinct by account name.
on the CRM UI, alas, I constantly get duplicates by account name (and i have double checked the fetchxml to be to set true for distinct).
But still, thank you so much.
MrE
The UI will always include the primary ID attribute of the main table to make the grid view work correctly – if you start from the intersect table this will lead to duplicates from the related tables. To make sure you get distinct accounts in the UI you’ll need to start from that table.
Hi Mark
Yes, thanks, I could see in the payload that it did add the primary id attribute even though I removed it on purpose :-).
What I wanted is that we could get to the “Basket” (entity) and find a distinct list of the accounts in this basket (and vice versa from the account have a look in which baskets they are in), even though they are related via this custom intersect table . The intersect table is required as we run processes on i, so there is no option to go via the N:N relationship hiding the intersection table.
Still pondering on a solution…
Kind regards
MrE
I almost managed it with editable grid and grouping with 2 caveats: I cannot pre-define the grouping and it appears expanded once grouped: so the user would have first to click group by account and then have to collapse and click the dozens of accounts. There is a microsoft idea for that with some attention. But I need a solution now 😉 … Hence, I continue pondering..